大模型测评报告:DeepSeek、豆包位于满意度第一梯队
2025-07-10 19:22


订阅
新京报贝壳财经讯(记者韦英姿 韦博雅)7月10日,在2025贝壳财经年会主题论坛“建设‘开源’之都:智AI未来,生态共澎湃”上,新京报AI研究院联合中国经济传媒协会发布第二期《中国AI大模型测评报告——大模型赋能传媒行业使用与满足研究》(下称:报告)。报告显示,在大模型产品媒体赋能效果满意度及使用频率统计中,DeepSeek、豆包位于第一梯队,受访者经常使用且对它们媒体工作赋能效果评价较高,分别占比 79.35%、58.06%。
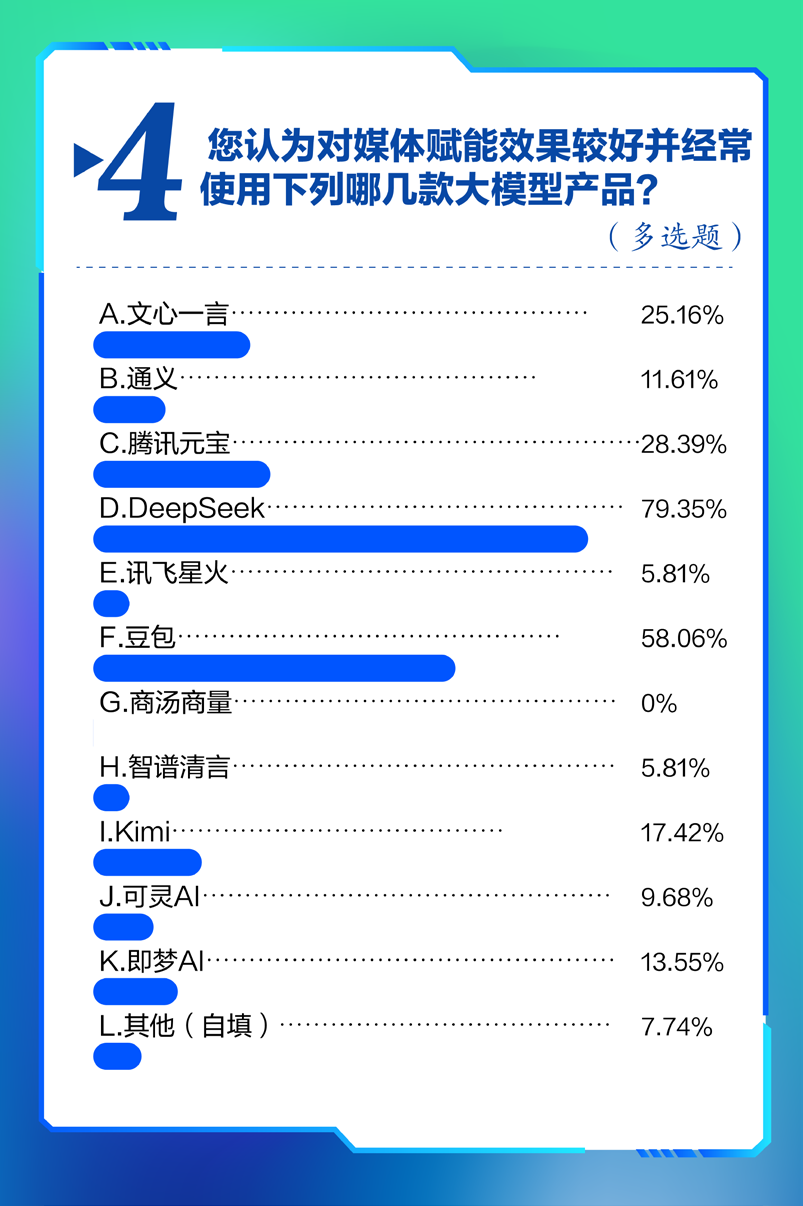
另外,腾讯元宝、文心一言位于第二梯队,受访者不常使用,且认为它们赋能媒体工作的效果一般,分别占比 28.39%、25.16%;Kimi、即梦AI、通义、讯飞星火等其余大模型产品位于第三梯队,受访者使用频率较低,且认为它们赋能效果有待改善,占比均低于20%。
报告交叉分析发现,受访者性别、从事报道领域和媒介属性不同,所青睐的大模型产品也略有差异。例如,在女性受访者中,日常使用DeepSeek、豆包、文心一言的人数较多,分别占 比79.12%、60.44%、24.18%;在男性受访者中,选择 DeepSeek、豆包、腾讯元宝的人数居多,分别占比73.91%、49.28%、39.13%。
编辑 王进雨
校对 卢茜











