

要看懂一幅中国画
并不容易
审美能力需要长期的积累和训练
那么,AI能看懂中国画吗?
当你让AI解读一幅山水或人物画
它可以生成一篇长篇大论
但问题是——
它是真的看懂了,还是只是看起来很懂?
北京大学「智镜」项目
就是为了解答这一个问题
给AI建了一套“中国画考试系统”
AI来答题,人类专家来阅卷
通过“考试”排名
不仅能客观比较不同AI的中式审美水平
也能找出它们在历史背景、文化常识方面的错误
从而为AI的本土化调优指明方向
(文末有“考官”体验入口!)
北京大学「智镜」项目,是首个致力于构建“中国传统审美”多模态大模型(LLM)评测基准的学术平台。由北京大学艺术学院、北京大学计算艺术实验室研发,旨在为AIGC的审美评测与质量控制提供具有中国文化深度的量化数据支撑。
大模型是否真正理解中国艺术?
「智镜」始于2025年3月,源于对大模型审美能力的思考。北京大学艺术学院李洋教授团队对于全球范围内的大语言模型进行了广泛调研。研究发现,当前主流评测体系大多基于通用任务与西方美学框架。而中国古代艺术体系成熟、内涵复杂,却长期缺乏一个能够对AI表现进行系统评估的标准。
因此,在北京大学-东湖高新区国家智能社会治理实验基地 “人文社科项目群”课题的支持下,北京大学艺术学院「智镜」项目组正式成立。李洋教授团队首先对大语言模型是否改变人的审美体验做了专题调研,团队对2700所高校大学生从2016年到2024年撰写的20000多篇报告入手,不仅发现大学生使用大语言模型的情况在2023年和2025年有了明显上升,更分析出他们运用大模型进行表达时,出现了个人体验反思的外包与审美升华的悬置,在“无痛自我感知”与“理论反思”两个维度上都体现出明显的变化。
于是,“智镜项目”针对大语言模型的审美问题应运而生,基于北京大学计算艺术实验室跨学科优势,尝试建立一套根植于中国自身美学传统的评估体系,将意境、气韵、神采等中国审美范畴转化为可被AI测试与迭代的具体指标。
如何量化“中国美”?
「智镜」的思路其实很简单:让真正懂中国艺术的人,来判断哪个AI说得更好。
要实现这个想法,需要解决三方面的问题。
首先,用哪些画来测试?
作为数据源,“智镜”构建了涵盖18,000+张中国艺术图像数据库,以古代书画为核心,逐步扩展到多种门类;每件作品同步整理创作背景、风格流派、文化寓意、评论文献等文本信息,形成“图像 + 文本 + 文化”三位一体的数据基础。
其次,测哪些模型?
平台已集成来自ByteDance、Tencent、OpenAI、Anthropic、Google、Meta、Qwen、THUDM、X.AI等机构的28个多模态大模型,在统一接口、统一作品、统一指标下进行持续的评测与动态排名。
最后,找哪些专家?
在智镜项目中,已完成两轮评测的70余位评审专家来自北京大学、清华大学、南京大学、浙江大学、中央美术学院、中国美术学院、南京艺术学院、河北美术学院等高校与研究机构,以中国古代美术史与相关方向的学者和博士生,负责完成作品对战和测评,并对大模型的审美表现进行反馈和评价,以此成为大模型审美排行版的基础数据。
第三期测评,四川美术学院、广州美术学院、鲁迅美术学院、湖北美术学院等更多院校加入智镜计划,30多位在高校任教的艺术史学者组成测评团队。
开始对战!
智镜搭建起了一个对战的平台。AI是对战选手,专家作为裁判。
专家通过网页端进入系统,可按时代、题材浏览作品,查看实时模型排行榜,选择作品后系统自动载入图像与元数据。换句话说,让大模型围绕中国审美卷起来!

评测模式上,智镜项目让专家可以选择国际大语言模型评估的两种通行对战形式:匿名随机对战或由测评人指定两个模型对战,但对战的形式是“盲评”,即不给大模型提供任何图像理解之外的信息。

选定后,两个模型将分别对这幅作品进行解读,生成一篇长文章。专家选择偏好选项(A更好 / B更好 / 两者差不多 / 两者都不好),并可从作品信息准确性、构图分析、笔墨技法、意境解读等多个维度填写简要理由。

根据专家们的投票结果,系统基于Bradley–Terry及Elo算法实时更新模型排行榜。
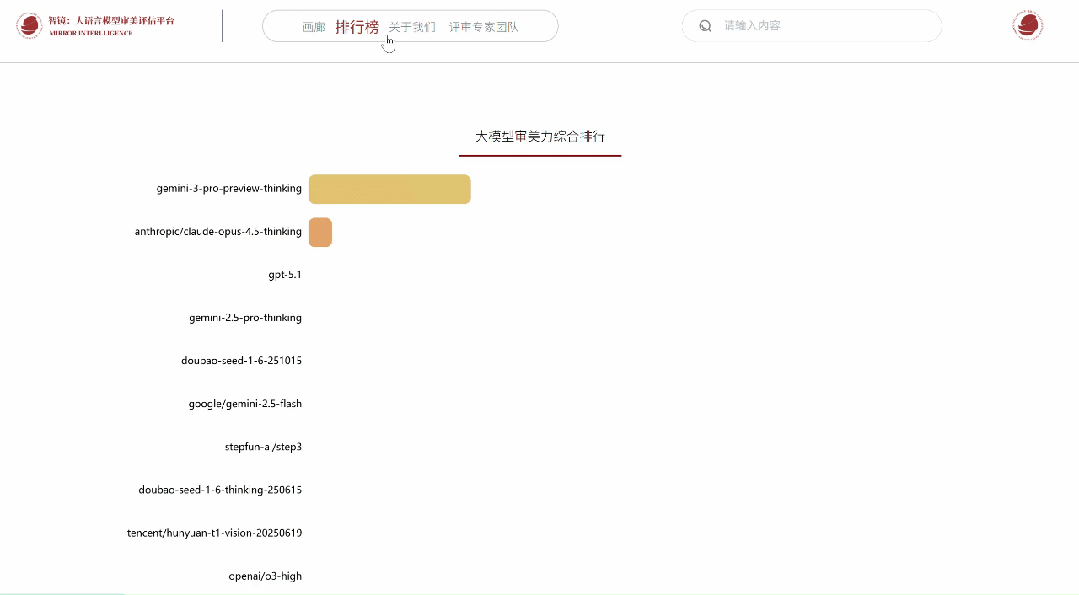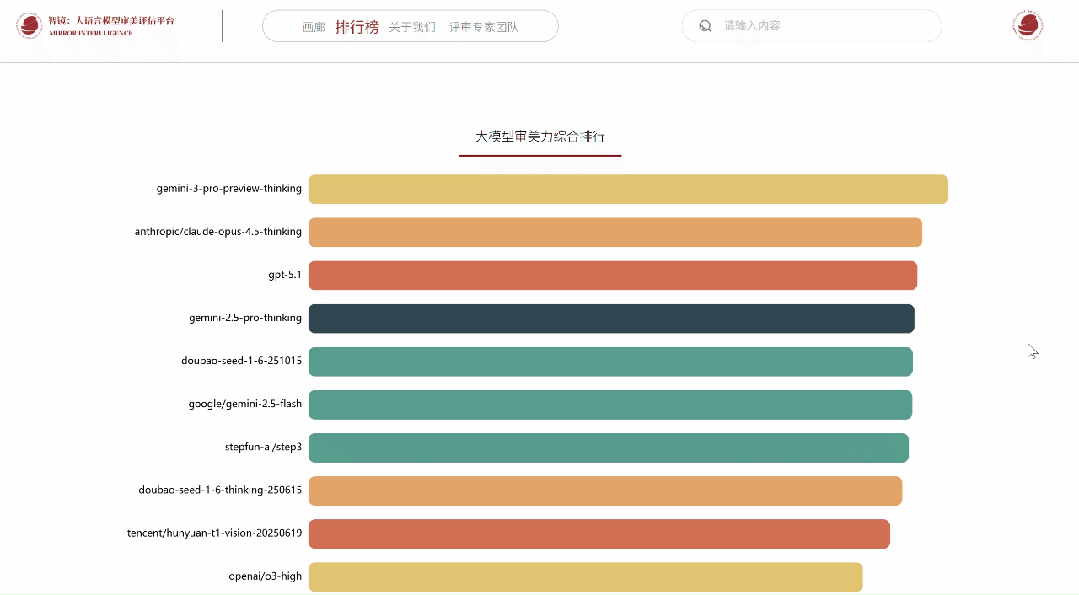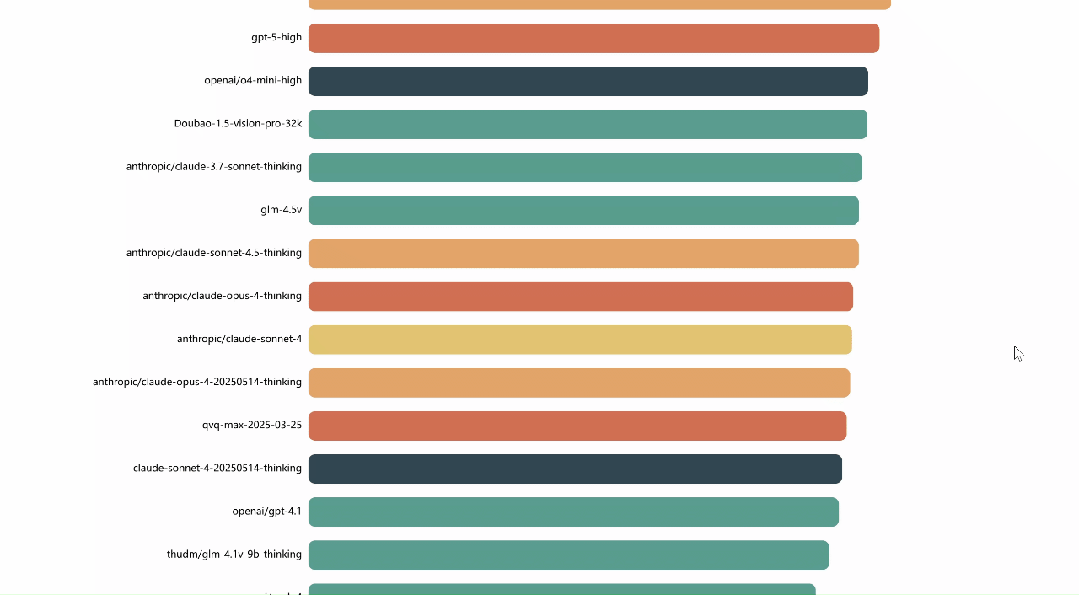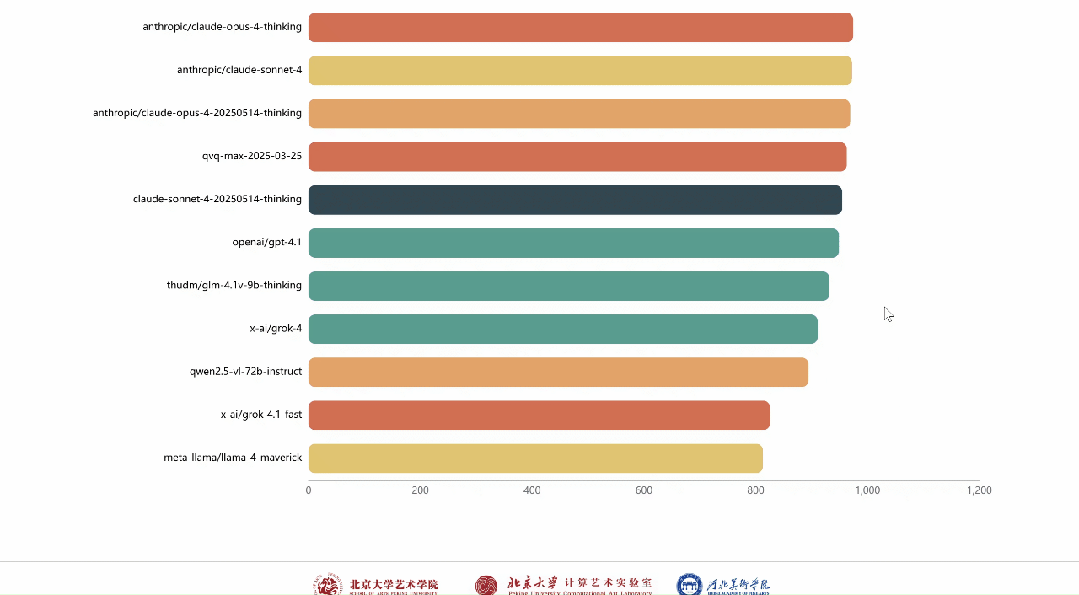
作为专家,可在个人中心查看历史投票记录与参与详情。
体验入口
「智镜」项目当前只对邀请的专家开放注册
计划于2026年5月正式对公众开放
目前,公众可通过以下链接体验评测:
http://mi.pku.edu.cn
(复制链接在浏览器打开,或点击“阅读原文”)
未来规划
「智镜」项目首次系统构建了基于中国美学传统的多模态大模型评测基准,使气韵、意境等范畴成为可量化维度。同时,将美学理论转化为可持续使用的评测系统,支持不同模型在同一标准下反复测试,也为后续研究提供基础设施。此外,通过识别模型在审美范式、历史背景、文化常识等方面的典型错误,为模型的本土化调优提供明确方向。
未来,「智镜」将持续拓展其评测体系的深度与边界。在现有图像评测基础上,项目第二阶段计划逐步引入文本、音乐、视频及三维场景等多模态内容,考察大模型在不同媒介中的审美理解与审美生成能力。
在评测机制上,项目将进一步完善专家参与结构,除了博士生和青年学者,项目第二步会邀请艺术史教授与美学学者组成专家委员会,完善理论框架与评分校准,进行测评打分;第三步,项目会邀请中国的艺术家展开测评,从创作实践角度对评测结果进行复核与修正。测评专家团队还会从国内拓展到国际专家团队,以让评测结果更加客观公正。智镜项目还计划对公众开放,邀请所有关心大语言模型审美问题的网友参与测评打分。
同时,「智镜」将以开放姿态推进生态共建,联合高校、科研机构及相关行业力量,定期发布审美评测结果,开发面向公众的互动产品,逐步将平台建设为一个连接技术、文化与社会的公共空间。
为AI“照镜”
为 AI“照镜”,是「智镜」项目的核心隐喻。
它希望搭建连接大众、专家与AI的桥梁。通过学者与艺术家的专业评审,将中国传统美学转化为算法可理解的评估体系;同时借助可视化的榜单与交互界面,向公众清晰呈现AI对中式艺术的认知水平,推动技术在多方对话中持续校准,实现对中国之美的守护与创新诠释。“智镜”项目关注中国审美在人工智能时代是如何被吸收和表达的,以及中国审美的传承与安全。
「智镜」之名,寓意深刻。它既包含审美观照的涵义,也蕴含技术自反的思考。
项目发起人李洋教授指出,「智镜」的直接契机,源于对“AI 审美污染”的警觉。当生成变得过于轻易,人们也可能逐渐将想象与体验外包给机器,陷入一种无意识的审美退化。
“在 AI 时代,我们仍然需要讲美。”在他看来,人文学科有责任在技术飞速发展的进程中,提出清晰而有立场的价值判断。而在北大,这一责任尤显深刻和迫切。
因此,「智镜」不仅是一项评测工具,更希望成为一个倡导AI时代审美价值、推动技术向善、弥补全球知识生产与审美体系中不平等现象的重要节点。
在一个被算法与生成内容不断包围的未来,「智镜」试图守住的,是人类感受世界、理解美、创造意义的能力。它所照见的,是我们在技术洪流中,是否仍愿意为“美”保留判断与思考的空间。
来源 | 北京大学融媒体中心、北京大学艺术学院
采写 | 张祺祺、来家君、徐周雨宣
排版 | 顾馨月
编辑&责编 | 岁寒


特别声明:本文为新京报客户端新媒体平台"新京号"作者或机构上传并发布,仅代表该作者或机构观点,不代表新京报的立场及观点。新京报仅提供信息发布平台。










